
High availability with CPU and network redundancy on Nexto and Hadron Xtorm series
For critical applications, with a 24/7 workload and operating at very high speeds, a failure which results in the shutdown of the plant can result in considerable damage to the company. As we saw in the article about the importance of redundancy in industrial automation systems, several market segments use redundant architectures to prevent the operation plant from crashing if a piece of equipment becomes unavailable.
With embedded high technology, adhering to the most advanced industry applications, Nexto Series programmable controllers and Hadron Xtorm remote terminal units have hardware and software redundancy at different levels. In this article, we talk about the redundancy features available in two of Altus` most advanced product series, as well as their applications and main features.
CPU redundancy on Nexto and Hadron Xtorm series
Both Nexto and Hadron Xtorm series count on redundant CPUs. In Altus` most advanced family of PLCs, redundancy is configured through Hot Stand-by. In simple terms, a redundant Hot Stand-by control system has two CPUs, one primary (active), responsible for controlling the system in operation, and a reserve (that we call stand-by).
In case any failure occurs and the main CPU becomes unavailable, the stand-by equipment automatically takes over the process control, without the need for an operator action and without causing losses to the plant`s operation. This exchange of functions between devices is known as switch-over.

To use the feature on Nexto Series, the architecture must have two identical complete backplanes (half-cluster), each with an NX3030 CPU, model with redundancy support, and an NX4010 module, Nexto redundancy link. With two embedded Ethernet communication interfaces, the NX4010 modules are responsible for creating the connection between the two racks (active and stand-by), keeping the secondary CPU updated and triggering the switch-over procedure.
To see more details about CPU redundancy in Altus PLCs, download Nexto Series User Manual.
Hadron Xtorm Series, on the other hand, has a redundancy configuration different from Nexto Series: it is applied in the same rack. For this, the power supplies and the HX3040 CPUs must be installed side by side, as the redundant data connection is made through the backplane bus. In this model, synchronization takes place through a hardware and software interface dedicated to this function within the CPUs.
Switch-over activation
There are some common types of failures in automation systems that can cause switch-overs between CPUs, with the main ones being:
- Hardware failure
- Power failure
- Removal of the controller from the rack
- Communication failure
The redundancy status can be viewed in the programming software and through the LCD display of the CPUs, with the replacement procedure being activated through some commands, such as those listed below:
- Received from programming software or a SCADA system
- Generated by the user application due to other diagnostics, such as Ethernet communication failure
- Diagnostic button present on CPUs (Hadron Xtorm Series)
- PX redundancy control panel (Nexto Series), which has the ability to completely turn-off a half-cluster if necessary

Definition of functions and sync channel redundancy
The CPUs themselves define the primary and stand-by functions autonomously during boot, with no user action required. Both units are loaded with the same programs and process data, with online update of spare CPU operands through the synchronism channels. These channels have the function of synchronizing redundant variables, diagnostics, redundant user memory area, event queue, project and commands.
Download the User Manual from Hadron Xtorm Series here and see more details about the resource.
Network redundancy on Nexto PLCs
In addition to CPUs, Nexto products technology also allows the configuration of field network redundancy (PROFIBUS and MODBUS), which further increases the level of availability in distributed system architectures. This type of resource allows the application to operate normally even during a failure in one of the redundant networks, offering greater availability, an essential characteristic in critical applications.
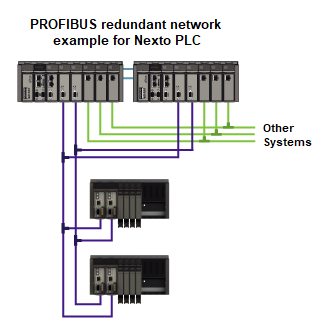 In the case of PROFIBUS networks, to use a redundant architecture it is necessary that the bus of each half-cluster count on a pair of NX5001 modules, PROFIBUS master of Nexto Series. The master modules are then connected with the also redundant pair of field remotes responsible for communicating with the distributed I/O modules – which can be the NX5210, our PROFIBUS-DP redundant remote model.
In the case of PROFIBUS networks, to use a redundant architecture it is necessary that the bus of each half-cluster count on a pair of NX5001 modules, PROFIBUS master of Nexto Series. The master modules are then connected with the also redundant pair of field remotes responsible for communicating with the distributed I/O modules – which can be the NX5210, our PROFIBUS-DP redundant remote model.
In network redundancy, each slave device has two network interfaces connected to two NX5001 modules. Each pair of redundant remotes controls a bus of Nexto Series I/O modules, alternately, one in the network (active) and the other in the reserve, which can take control of the bus if there is a fault in the network or in the active head hardware. This control exchange is automatic and transparent to the user, keeping the system operating in the case one of the networks fails.
The redundancy in MODBUS network architectures is done through NX3030 and NX3020 CPUs, Nexto Series models with two Ethernet interface ports.
Ethernet Redundancy with NIC Teaming
Network Interface Card Teaming, or NIC Teaming, is a strategy that allows using two Ethernet interfaces of a CPU to form a redundant pair and share the same data and the same IP address. In this way, redundant Ethernet networks can be built more easily, with implementing complex scripts to switch IP addresses between the clients connected to a NIC Teaming pair.
The resource can be used, for example, when communicating with a supervisory network. In this case, the two Ethernet interfaces that form the NIC Teaming pair connect to two different switches that, at some point, will interconnected. This type of architecture allows a high availability rate for the system, strongly indicated to prevent failures in Ethernet ports, cables and switches.
Advanced diagnostics
As already mentioned, automatic switching between CPUs in redundant architectures is a feature that exceptionally increases application availability and security. However, this silent transition can mask some failures (called “hidden failures” – when there is a failure and the operation or maintenance team is unaware of) which results in serious problems for the operation in the future.
To prevent these hidden faults from occurring, the Nexto and Hadron Xtorm series products have an extensive list of diagnostics, such as:
- One Touch Diag
- LED diagnostics
- WEB diagnostics
- Variables diagnostics
- Function Blocks diagnostics
These resources are able to identify and alert the process operator about the occurrence of application failures at the time of the switch-over between the active and reserve modules, even if the process hasn’t suffered any discontinuity or unwanted stop.
For more information about Nexto PLCs diagnostics, download the CPUs utilization manual.
Possibility of Hot Swap
Both Nexto Series PLCs and Hadron Xtorm RTUs have I/O modules with hot swap support, which minimizes system downtime for maintenance, further increasing the application`s availability level. The functionality allows the replacement or removal of components present in an electronic device, in this case, a PLC, without the need to turn it off. That is, these components can be handled while the controller continues to operate.



